竞赛总结:KDD2024 OAG-Challenge
比赛名称:KDD2024 OAG-Challenge
比赛类型:自然语言处理、大模型
比赛任务:学术数据挖掘
https://www.biendata.xyz/kdd2024/
赛题背景
学术数据挖掘(Academic Data Mining)是利用数据挖掘技术来分析和理解科学发展、本质和趋势的过程。
通过分析学术数据,政府可以更好地理解科学领域的发展趋势,从而制定更有效的科学政策。
企业可以通过分析学术数据来识别潜在的人才,这对于招聘和团队建设至关重要。
研究人员可以利用学术数据挖掘来更高效地获取新知识,加速科研进程。
尽管学术数据挖掘的潜力巨大,但社区在推进学术图挖掘(Academic Graph Mining)方面遇到了挑战,主要原因是缺乏合适的公共基准数据集。学术图挖掘是指在学术领域内,通过图结构来表示实体(如作者、论文、会议等)及其相互关系,并进行分析的过程。
为了解决这一问题,KDD Cup 2024(知识发现和数据挖掘大会杯,是一个国际知名的数据挖掘竞赛)提出了开放学术图挑战(Open Academic Graph Challenge,简称OAG-Challenge)。这个挑战包括三个现实且具有挑战性的数据集,旨在推动学术图挖掘技术的发展。
赛题任务
OAG-Challenge是一个专注于学术图挖掘的竞赛,它包含了三个任务,每个任务都旨在评估学术图挖掘的不同方面。
WhoIsWho-IND(作者名字消歧任务)
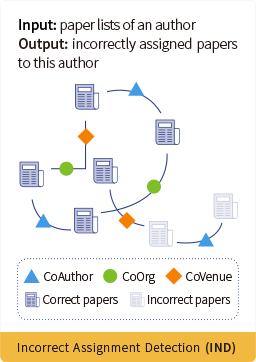
给定每位作者的个人资料,包括作者姓名和发表的论文,参赛者需要开发一个模型来检测论文中错误分配给该作者的论文。此外,数据集还提供了所有涉及论文的详细属性,包括标题、摘要、作者、关键词、地点和发表年份。
AQA(学术问题回答任务)
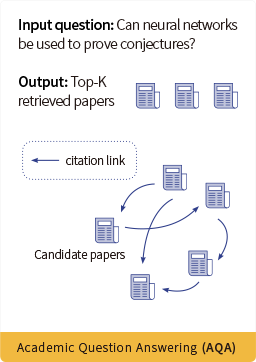
在本任务中,参与者的任务是使用问题-论文对来训练检索模型。该数据集来源于OAG-QA,OAG-QA从StackExchange和知乎网站检索问题帖,提取答案中提到的论文URL,并将其与OAG中的论文进行匹配。参与者将获得问题数据集,并需要找到与这些问题最匹配的论文。
PST(论文来源追踪任务)
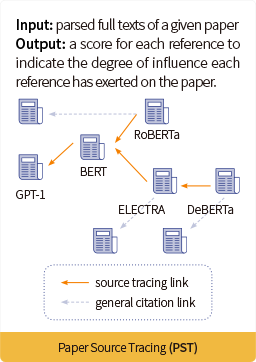
论文源头追溯任务的目的,是在给定一篇论文p的全文的情况下,从这篇论文中找出ref-source。ref-source即最重要的参考文献(叫做“源头论文”),一般是指对本篇论文启发性最大的文献。每篇论文可以有一篇或多篇ref-source,也有可能没有ref-source。对于论文的每一篇参考文献,论文源头溯源都要给出一个范围在[0, 1]的重要性分数。
评价指标
WhoIsWho-IND(作者名字消歧任务)
我们采用异常检测中广泛采用的 AUC作为评估指标。对于每个作者,
对于所有作者( 是作者数量),
AQA(学术问题回答任务)
我们利用平均精度 (MAP) 和 top-k MAP 作为评估指标。
对于每个问题 , 平均精度(AP)将根据以下公式计算:
其中 是标记为正例的论文 ID 的数量, 表示数据库中论文的数量, 是问题 的排名列表中截止第 个的精度。 是一个指示函数;如果第 个返回的论文偏好符合标准答案, ,否则 。
对于给定的 个问题,我们将用以下方式计算MAP:
PST(论文来源追踪任务)
我们将计算结果的 (平均精度均值)进行打分和排名。对于测试集中的每篇论文会先计算 (平均精度), 的计算公式如下:
其中 是正例(重要参考文献)的数目, 是对排名列表中截止第 个的精度, 是真实的标注结果,取值为 0 或 。 0 为负例,非重要参考文献, 1 为正例,重要参考文献。 表示该论文的参考文献数目。然后计算所有论文的 的均值,得到 :
优胜方案(IND赛题)
NJUST
https://openreview.net/attachment?id=1mYLGW4OqL
原文链接:https://www.normaera.com/competition/10352.html